
Engineers across the industry are reporting the same thing: AI tools like Claude and Cursor have genuinely made them faster, but they don’t feel better for it. Work that used to take two days now lands in half a day — yet by the end of that half day they’re as drained as they used to be after two full days. The fatigue didn’t shrink with the timeline. It got concentrated.
This is worth taking seriously. The intuition behind it is correct, and it’s showing up everywhere, not just in any one team or company.
What’s actually happening
A two-day task was never two days of peak effort. It had natural lulls — waiting on a build, reading docs, a slow stretch of plumbing code, a pause while an idea settled. Those low-intensity moments were unplanned recovery. They let your attention recharge between the genuinely hard parts.
AI strips out the plumbing, the boilerplate, and the slow stretches. But it strips out the recovery along with them. What’s left is the hard core of the work — the judgment calls, the decisions, the checking of generated code — packed back-to-back with nothing in between. The day becomes a denser run of high-effort moments. Higher output, less recovery, the same or greater total exhaustion.
That’s the compression problem in one line: AI compressed the work, but it also compressed the rest that used to be built into it.
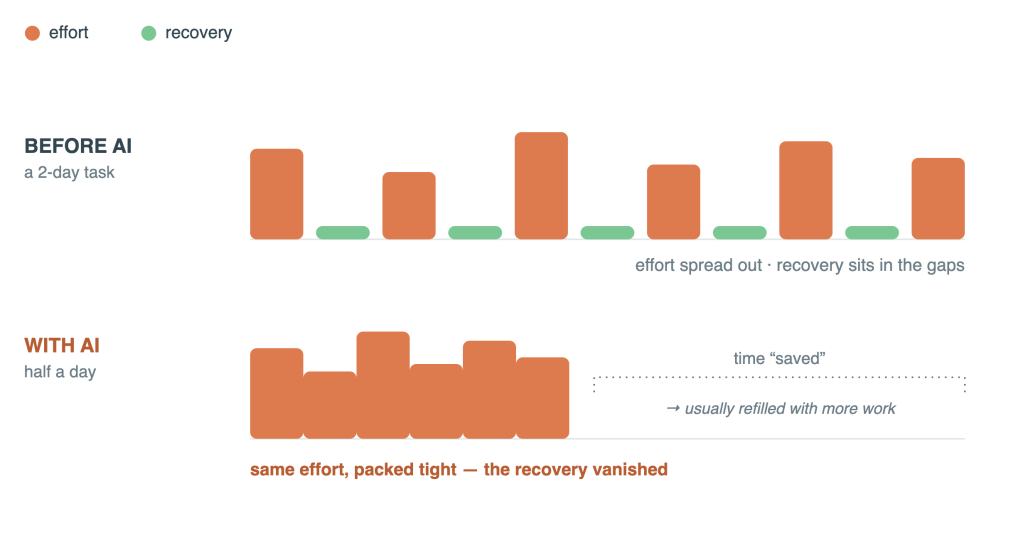
This is an industry-wide pattern
The data backs the engineers up:
- They’re juggling more, not less. Teams using AI heavily open about 47% more pull requests per day and touch far more tasks in parallel (Faros AI, 2025). More parallel work means more context-switching — the most draining kind of mental load.
- The work shifted from writing to reviewing. AI generates large chunks of plausible code that someone still has to read, understand, and trust. Reviewing dense code is more tiring than writing your own, and there’s now more of it.
- People feel faster than they are. In the most rigorous study to date, experienced developers were actually ~19% slower with AI — yet were convinced they’d been faster (METR, 2025). That gap matters: when everyone assumes the work should now be dramatically quicker, the saved time immediately gets refilled with more work instead of banked as breathing room.
- Speed up front, instability out back. Google’s DORA research has repeatedly found AI lifts individual productivity but reduces delivery stability — meaning more rework and more incidents downstream. The faster front door feeds a heavier back door.
The most encouraging finding is also industry-wide: DORA found teams with stable priorities have roughly 40% less burnout. So this is a management-and-systems problem, not a willpower problem — which means it’s fixable with the levers leaders already hold.
One amplifier worth noting for any team that runs an oncall rotation: AI shrinks feature work, but it doesn’t shrink the incident queue or the support backlog. So engineers hit dense, compressed feature bursts and an unchanged stream of interrupts on top — two heavy loads colliding with no slack between them. An oncall page is itself a forced, high-stakes context-switch, the single most expensive kind.
A few solutions
These are scoped to what a team and its manager can actually control — no waiting on a vendor.
- Stop auto-refilling the time AI saves. The default failure mode is that saved hours quietly turn into more tickets. Treat some of that recovered time as banked recovery, not new capacity. Cap how many things any one engineer is juggling at once.
- Separate “make” load from “interrupt” load. Don’t stack compressed feature work on top of an active oncall week. Whoever is on rotation should carry materially less feature commitment — the rotation is the load.
- Keep changes small. Large AI-generated PRs are harder to review and more destabilizing. Push generated work into small, reviewable units, and move validation earlier (into the IDE and CI) so people aren’t yanked back to “finished” work later.
- Measure outcomes, not editor activity. Track working software, low rework, and stable delivery — not lines generated or how fast it feels. Saying the perception gap out loud (“you’re probably not as much faster as it feels, and that’s fine”) removes the self-imposed treadmill.
- Make recovery legitimate. Short breaks and mentally stepping away aren’t slacking — they’re what restores the capacity dense work burns through. Give explicit permission to take the gap between two intense tasks, and have managers model it (not pinging late, not treating a quiet afternoon as a problem).
- Watch the early-warning signs. Velocity rising while wellbeing falls is the trap. Keep an eye on parallel-task count, PR size, after-hours activity, and oncall interrupt frequency. Rising numbers there show up weeks before attrition or a missed incident does.
Bottom line
The engineers are describing something real. AI didn’t fail — it did exactly what it promised and made the work faster. The catch is that it also removed the natural pauses that made sustained intensity survivable. The fix isn’t less AI; it’s redesigning the work so the time AI gives back is partly returned to people as rest, and so interrupt load and feature load stop colliding with nothing in between. Throughput and sustainability aren’t in conflict — treating recovered time as slack rather than capacity is how you get both.
